
郑州中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2020-07-14 来源:黑马程序员 浏览量:
缓存只是为了缓解数据库压力而添加的一层保护层,当从缓存中查询不到我们需要的数据就要去数据库中查询了。如果被黑客利用,频繁去访问缓存中没有的数据,那么缓存就失去了存在的意义,瞬间所有请求的压力都落在了数据库上,这样会导致数据库连接异常。
针对缓存穿透的常见解决方案有以下两种:
方案1: 对于数据库中不存在的数据, 也对其在缓存中设置默认值Null,为避免占用资源,一般过期时间会比较短;
方案2: 可以设置一些过滤规则, 如布隆过滤器
方案1:相对简单, 但是也容易破解, 比如 攻击者通过分析数据格式, 不重复的请求数据库不存在数据, 那这样方案1就等于失效的. 相对而言,
方案2则更加稳定, 接下来就主要讲解一下方案2的实现方式。
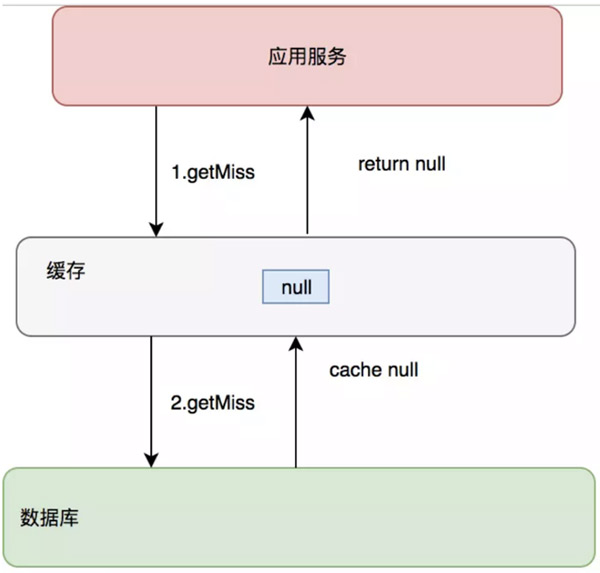
方案2的设计思路是通过设置过滤规则, 在数据库查询之前将数据进行过滤, 如果发现数据不存在, 则不再进行数据库查询, 以此来减小数据库的访问压力。
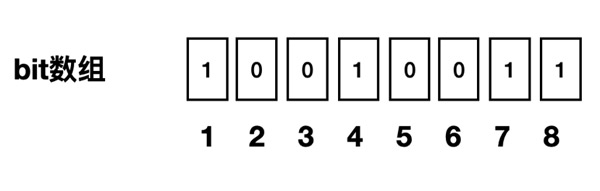
方案2中过滤规则目前主流的一种的载体就是布隆过滤器. 布隆过滤器是一种概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”.
相比于传统的 List、Set、Map 等数据结构,布隆过滤器是一个bit数组,
它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
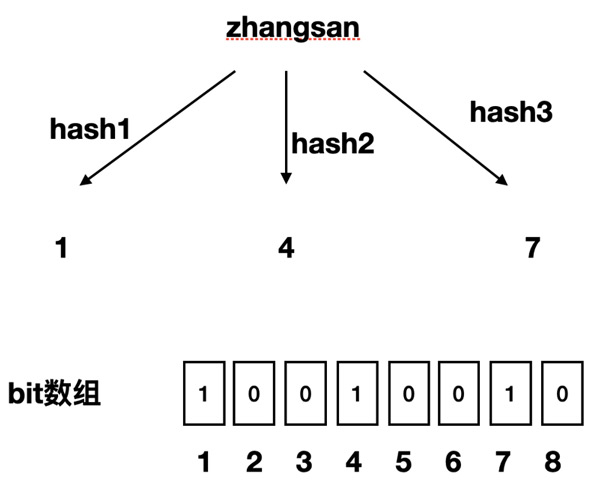
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值
“zhangsan” 和三个不同的哈希函数分别生成了哈希值 1、4、7
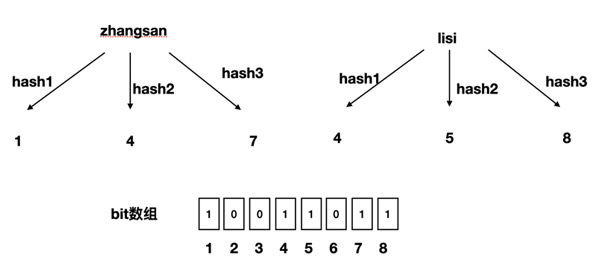
我们现在再存一个值 “lisi”,如果哈希函数返回 4、5、8 的话,图继续变为:
当我们想要判断布隆过滤器是否记录了某个数据时,布隆过滤器会先对该数据进行同样的哈希处理, 比如 “wangwu”的哈希函数返回了
2、5、8三个值,结果我们发现 2 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “wangwu”
这个数据不存在。
但是同时我们会发现,4 这个 bit 位由于”zhangsan”和”lisi”的哈希函数都返回了这个 bit 位,因此它被覆盖了。那么随着布隆过滤器保存的数据不断增多, 重复的概率就会不断增大, 所以当我们过滤某个数据时, 如果发现其三个哈希值都在过滤器中进行了记录, 那么也只能说明过滤器中可能包含了该数据, 并不能绝对肯定, 因为可能是其他数据的哈希值对结果产生了影响.这也就解释了上文所说的 布隆过滤器只能说明“某样东西一定不存在或者可能存在”.至于为什么采用三种不同的哈希函数取值, 因为三个哈希值只要有一个不存在就说明数据一定不在过滤器中, 这样做是可以减小因哈希碰撞(两个数据的哈希值相同)产生的错误概率.
布隆过滤器在很多语言中都有封装的工具包, 下边以python的工具包pybloomfiltermmap3 为例演示一下代码:
import pybloomfilter
# 创建过滤器(数据容量, 错误率, 存储文件) 错误率越低, 文件越大
filter = pybloomfilter.BloomFilter(1000000, 0.01, 'words.bloom')
# 添加数据
filter.update(('bj', 'sh', 'gz'))
# 判断是否包含
if 'bj' in filter:
print('包含')
else:
print('不包含')
猜你喜欢:
python培训课程




















.jpg)